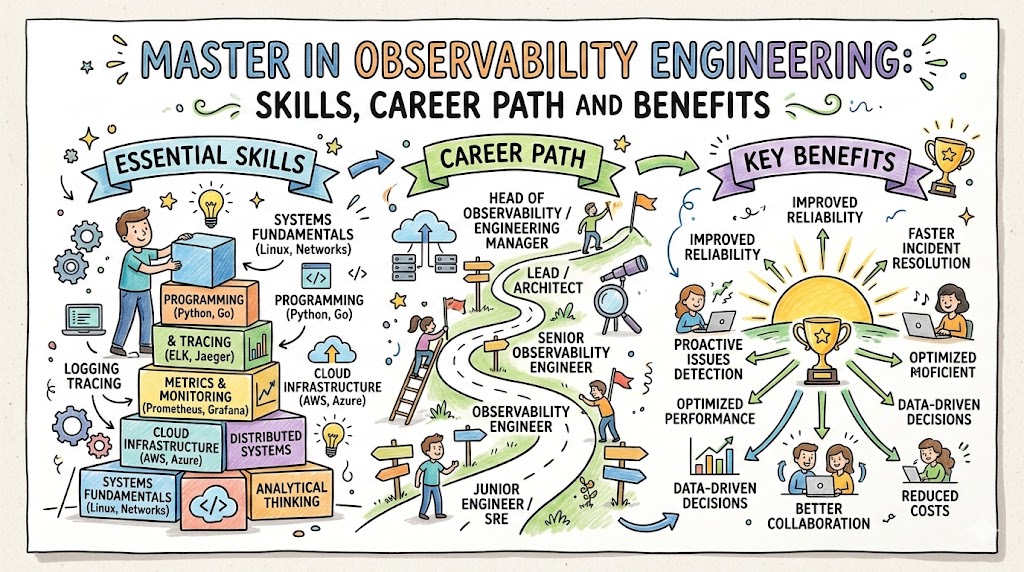
Introduction
Modern digital systems are no longer simple, single‑server applications. They span microservices, containers, cloud platforms, APIs, and third‑party integrations, all changing several times a day. In this reality, teams cannot rely only on basic dashboards or a few CPU graphs to keep customers happy.This is where Observability Engineering steps in. It gives you the ability to “see inside” your systems through telemetry—metrics, logs, traces, and events—and turn that data into fast, confident decisions. The Master in Observability Engineering certification from DevOpsSchool is designed for professionals who want to go beyond traditional monitoring and become the people who design, own, and improve observability for complex environments.As someone with two decades in DevOps, SRE, and large‑scale production systems, I can say clearly: people who understand observability deeply become central to every high‑performing engineering organization. This guide walks you through what MOE is, who it suits, what you learn, how to prepare, and how to connect it with long‑term career growth across DevOps, DevSecOps, SRE, AIOps/MLOps, DataOps, and FinOps.
Observability Engineering in Simple Terms
Observability Engineering is about designing systems so that you can easily understand their internal behavior from the outside. Instead of guessing why something is slow or failing, you collect rich signals—logs, metrics, traces—and analyze them quickly to find the real problem.An Observability Engineer works across application code, infrastructure, and tools. They help teams decide what to measure, how to instrument services, how to route telemetry, how to build useful dashboards, and how to connect observability with SLOs, incidents, and business goals. In many companies, this role overlaps with DevOps Engineer, SRE, Platform Engineer, or Senior Software Engineer responsibilities.
Why Observability Has Become Non‑Negotiable
Today’s systems have a few common traits: they are distributed, fast‑changing, and critical for business revenue. A single customer request might go through dozens of services, message queues, and databases before returning a response. When something breaks, teams need answers in minutes, not days.
Strong observability helps teams to:
- Detect issues early, before customers raise tickets.
- Pinpoint the exact service, region, or dependency causing trouble.
- Understand user and business impact through SLIs, SLOs, and error budgets.
- Learn from incidents and build more reliable systems over time.
Because of this, organizations are actively searching for engineers who can lead observability design and implementation, which is exactly the gap the Master in Observability Engineering aims to fill.
Core Skill Areas Covered in MOE
From the official agenda and supporting material, the MOE certification builds depth in the following areas.
- Observability foundations: pillars, principles, and best practices.
- Logs, metrics, traces, and events—how to design and use each effectively.
- Time‑series data and dashboards (Prometheus/Grafana‑style patterns, etc.).
- Distributed tracing for microservices and service mesh architectures.
- OpenTelemetry architecture, components, SDKs, and collectors.
- Telemetry pipelines: collectors, processors, exporters, and storage backends.
- Cloud‑native observability on Kubernetes and container platforms.
- Alerting strategy, SLIs/SLOs, incident response, and root cause analysis.
- Advanced analysis and anomaly detection using cloud tools and AI/ML.
These skills make you capable of designing observability for both new systems and existing legacy or hybrid environments.
Master in Observability Engineering – Deep Dive
What it is
The Master in Observability Engineering is a specialized certification that turns you into a practitioner who can design and run observability across complex, cloud‑native systems. It moves you beyond tool usage into architecture, instrumentation patterns, and incident‑ready telemetry.
Who should take it
- DevOps, SRE, and Platform Engineers who own production stability.
- Backend and full‑stack developers who want to ship observable services.
- Cloud and Infrastructure Engineers working on multi‑cloud or hybrid setups.
- Engineering Managers responsible for uptime, SLOs, and incident processes.
Skills you’ll gain
- Clear mental model of observability vs traditional monitoring.
- Ability to design observability architecture and telemetry flows.
- Hands‑on capability with OpenTelemetry (SDKs, collectors, exporters).
- Skill in building meaningful dashboards, alerts, and SLO/SLI frameworks.
- Familiarity with observability in Kubernetes, microservices, and service mesh setups.
- Experience applying anomaly detection and advanced analytics to operations.
Real‑world projects you should handle after MOE
- Instrumenting a microservice‑based application with OpenTelemetry and routing data to an observability backend.
- Designing dashboards and alerts that track user experience (latency, errors) and system health.
- Building a telemetry pipeline including collectors, transformations, and exporters for logs, metrics, and traces.
- Defining SLIs and SLOs for key services, connecting them with error budgets and on‑call workflows.
- Running structured post‑incident reviews driven by observability data and improving systems iteratively.
Preparation plan (7–14 days / 30 days / 60 days)
7–14 days (Accelerated path)
- Days 1–2: Read the official MOE page carefully and list all key topics.
- Days 3–4: Focus on OpenTelemetry basics and simple instrumentation with sample apps.
- Days 5–7: Practice building dashboards and alerts from metrics, logs, and traces in at least one toolset.
- Days 8–10: Complete one mini end‑to‑end project: instrument, collect, visualize, and troubleshoot a small application.
- Days 11–14: Review SLO/SLI concepts, run through mock incident scenarios, and revise weak areas.
30 days (Steady professional path)
- Week 1: Fundamentals—observability concepts, monitoring vs observability, and pillars (logs, metrics, traces).
- Week 2: OpenTelemetry architecture and hands‑on labs with collectors and exporters.
- Week 3: Kubernetes and microservices observability; service mesh and distributed tracing use cases.
- Week 4: Design a realistic observability solution for a sample system (e‑commerce, banking, SaaS), plus focused exam practice.
60 days (Busy working engineer path)
- Weeks 1–2: Learn core theory and map it to your current environment.
- Weeks 3–4: Gradually instrument one service at a time in your real system using OpenTelemetry and improve dashboards.
- Weeks 5–6: Introduce SLOs, refine alerting, explore anomaly detection features, and finalize preparation with practice questions.
Common mistakes to avoid
- Treating observability as “just more logs” instead of a structured telemetry strategy.
- Ignoring tracing, which is critical for microservices, and focusing only on metrics.
- Configuring too many alerts without tying them to user impact and SLOs.
- Skipping OpenTelemetry and locking into a single vendor too early.
- Preparing only from slides and documents without building at least one real observability pipeline.
Best next certification after MOE
The natural “big picture” next step after MOE is a broad DevOps/SRE master program such as Master in DevOps Engineering (MDE) from DevOpsSchool, which we use here as reference. That track combines DevOps, DevSecOps, and SRE in one journey, letting you place your observability skills in a complete delivery and reliability context.
After MOE, adding MDE or similar multi‑discipline master training positions you as someone who can design CI/CD pipelines, embed security, and run reliable systems with strong observability.
Certification Table (Required Fields)
| Track | Level | Who it’s for | Prerequisites | Skills covered | Recommended order |
|---|---|---|---|---|---|
| Observability Engineering | Master / Advanced | DevOps, SRE, Platform, Cloud Engineers, Senior Developers, Tech Leads, Engineering Managers | Linux and scripting basics, cloud and CI/CD fundamentals, some production exposure recommended | Observability concepts, logs/metrics/traces, OpenTelemetry, telemetry pipelines, dashboards/alerts, SLOs/SLIs, incident response, cloud‑native observability, anomaly detection | After core DevOps/SRE foundations; early specialization for reliability‑focused roles |
Choose Your Path: Six Learning Paths Around MOE
1. DevOps Path
If your main focus is automation and delivery, take a core DevOps mastery program (like MDE) to learn CI/CD, infrastructure as code, and culture. Then layer MOE on top to ensure everything you build—pipelines, platforms, and apps—is observable from day one. Over time, you can grow into a DevOps Architect who also owns observability strategy.
2. DevSecOps Path
For engineers who care about both speed and security, combine DevOps fundamentals with DevSecOps training. Add MOE to design telemetry that surfaces security‑relevant signals such as unusual access patterns, failed logins, or policy violations. This path suits Security Engineers and DevSecOps specialists who want to make observability part of their defense strategy.
3. SRE Path
If you want to live at the reliability frontier, start with SRE concepts: SLOs, error budgets, incident response, and capacity planning. Use MOE to gain the concrete tools and techniques required to implement those ideas in real systems—designing observability for error budgets, on‑call, and incident automation. This is an ideal route for future SRE Leads and Reliability Architects.
4. AIOps/MLOps Path
For engineers interested in using AI to operate systems, begin with DevOps and some basic data/ML understanding. MOE gives you the telemetry quality required to feed AIOps engines—good signals, structured traces, and meaningful metrics. You can then grow into roles that design intelligent alerting and automated remediation pipelines powered by observability data.
5. DataOps Path
If your world is data platforms and pipelines, start with DataOps or data engineering programs. Apply MOE learning to monitor data freshness, pipeline health, failure patterns, and quality metrics using the same observability patterns used for apps. This blend is powerful for Data Engineers and Analytics Platform Owners.
6. FinOps Path
For those focused on cloud cost and business value, start with FinOps training. Combine this with MOE to correlate cost with usage, performance, and reliability using shared telemetry. With this path, you can help leadership see clearly how technical behavior (traffic, errors, scaling) affects cloud spend and ROI.
Role → Recommended Certifications (Mapping)
| Role | Recommended direction |
|---|---|
| DevOps Engineer | Core DevOps master program (e.g., MDE), then MOE to add deep observability for pipelines and production systems. |
| SRE | SRE‑centric training plus MOE to implement SLOs, SLIs, robust telemetry, and incident practices. |
| Platform Engineer | DevOps + cloud foundations plus MOE to design platform‑level observability and self‑service telemetry for internal teams. |
| Cloud Engineer | Cloud provider certifications plus DevOps basics plus MOE to monitor and troubleshoot workloads across regions and accounts. |
| Security Engineer | DevSecOps/security programs plus MOE to use observability for security detection and compliance evidence. |
| Data Engineer | DataOps/data engineering training plus MOE to observe pipelines, data quality, and SLAs. |
| FinOps Practitioner | FinOps specialization plus MOE to link telemetry with cost and optimize spend versus performance. |
| Engineering Manager | DevOps/SRE leadership programs plus MOE to set SLOs, define observability strategy, and lead incident governance. |
Next Certifications After MOE (Same Track, Cross‑Track, Leadership)
Using the Master in DevOps Engineering reference ecosystem:
1. Same‑track (Observability & Reliability Deepening)
- Advanced SRE or Reliability certifications focusing on SLO design, capacity, and chaos engineering.
- Tool‑specific advanced trainings (e.g., particular APM or logging platforms) once your company chooses a stack.
2. Cross‑track (DevOps, DevSecOps, AIOps)
- Broad DevOps master certifications such as MDE to add CI/CD, DevSecOps, and SRE in a single journey alongside MOE.
- AIOps or MLOps programs that use your observability data as input for automation and prediction.
3. Leadership‑oriented
- Leadership‑focused DevOps/SRE programs around transformation, culture, and organizational design.
- With MOE, these prepare you for roles like Head of Platform, SRE Director, or Observability Practice Lead.
Top Training & Certification Support Institutions
DevOpsSchool
DevOpsSchool is the official source for the Master in Observability Engineering certification and delivers the full MOE curriculum. It offers flexible formats—live online, self‑paced video, and corporate sessions—so both individuals and teams can learn effectively. Their portfolio also includes Master in DevOps Engineering and many related tracks, making it easy to design long‑term learning paths.
Cotocus
Cotocus focuses on structured, corporate‑grade training that connects learning outcomes to real project requirements. They are a strong choice for organizations that want to align MOE‑style learning with ongoing cloud, DevOps, or modernization programs. Their approach helps teams move from theory to implementation in a controlled and measurable way.
Scmgalaxy
Scmgalaxy is known for strong DevOps foundations, especially in source code management, build automation, and related tooling. This foundational knowledge makes it easier to apply observability principles later because you understand the full delivery pipeline. Engineers often use Scmgalaxy as a starting point before stepping into master‑level and observability programs.
BestDevOps
BestDevOps emphasizes practical DevOps skill building with clear structure and repeated exercises. It suits professionals who want guided practice rather than only lectures, helping them gain confidence over time. When combined with MOE, this approach supports engineers in turning observability concepts into regular day‑to‑day habits.
Devsecopsschool
Devsecopsschool offers focused DevSecOps and secure pipeline training. For MOE learners on a security‑heavy path, it teaches how to bake in security checks, logging, and evidence into CI/CD. That makes it easier to use observability data later for security analytics and compliance reporting.
Sreschool
Sreschool is dedicated to Site Reliability Engineering and reliability‑first thinking. Its programs are built around observability, error budgets, incident management, and high‑traffic operations. Pairing Sreschool with MOE is ideal for engineers who see their future as SRE Leads or Reliability Architects.
Aiopsschool
Aiopsschool specializes in AIOps—using AI and machine learning in IT operations. It teaches how to automate detection and remediation using data from tools and telemetry. MOE provides the telemetry quality AIOps needs, while Aiopsschool shows you how to turn that data into intelligent automation.
Dataopsschool
Dataopsschool focuses on DataOps, agile data pipelines, and data quality. With MOE in your toolkit, you can use their training to bring observability thinking into data engineering: tracking freshness, failures, and correctness as first‑class metrics. This is ideal for teams building analytics, real‑time dashboards, and ML data platforms.
Finopsschool
Finopsschool helps individuals and teams understand cloud financial management and FinOps practices. When combined with MOE, you can look at cost, performance, and reliability together, using shared telemetry rather than separate spreadsheets. This skill set is powerful for FinOps Practitioners, Cloud Architects, and Engineering Managers.
FAQs on Master in Observability Engineering (Difficulty, Time, Value)
1. How hard is Master in Observability Engineering?
MOE is advanced, but it is designed for working engineers and managers, not researchers. If you already understand basic DevOps and cloud concepts, the material will feel demanding but achievable with regular practice.
2. How much time do I need to prepare?
Plan 30–60 days if you are a full‑time professional, or 2–3 weeks if you already work with observability tools. The formal training itself typically covers 15–20 guided hours, with additional time for labs and revision.
3. What background is expected before starting MOE?
You should be comfortable with Linux, basic scripting, cloud services, and CI/CD ideas, plus some exposure to production or staging systems. Prior experience with logs or dashboards is useful but not mandatory.
4. In what order should I take MOE with other certifications?
If you are new to DevOps, start with a core DevOps or SRE program like MDE and then add MOE. If you already work in operations or backend roles, you can take MOE earlier to deepen your impact on reliability and incident handling.
5. What career impact can I expect?
MOE can help you step into roles such as Observability Engineer, Senior DevOps/SRE, or Platform Engineer with stronger responsibility for reliability. It also strengthens your profile for leadership roles that involve defining observability strategy and SLO governance.
6. Is MOE still useful if my company has a mature monitoring stack?
Yes, because MOE focuses on how to design and use observability systems effectively—not just on installing tools. Many teams own powerful platforms but lack good instrumentation and SLOs; MOE helps close that gap.
7. Does MOE actually cover OpenTelemetry in depth?
The official agenda includes introduction to OpenTelemetry components, architecture, collectors, and exporters, along with hands‑on configuration. This is a core part of making your observability architecture vendor‑neutral and future‑proof.
8. Is the certification recognized outside India?
DevOpsSchool has a strong base in India, but the content and practices are aligned with global SRE and observability standards. Engineers use these skills to work with international teams and roles as well.
9. Will software developers benefit from MOE?
Yes, because developers who understand observability write better, easier‑to‑debug services. MOE helps developers design proper logging, metrics, and traces directly in their code, leading to faster issue resolution.
10. How does MOE relate to SRE practices?
SRE relies on strong observability to track SLIs, manage SLOs, and analyze incidents. MOE provides the practical toolkit SREs need to build and evolve observability platforms that enable these practices.
11. Do I need Kubernetes experience?
Kubernetes knowledge is helpful because many MOE examples and modern observability scenarios involve containers and orchestration. However, you can start MOE while you are learning Kubernetes if you are ready to practice both in parallel.
12. How is MOE different from standard monitoring courses?
Most simple monitoring courses are tool‑centric and focus on configuration. MOE is architecture‑centric and incident‑oriented: it teaches you how to design telemetry, integrate OpenTelemetry, define SLOs, and use data for decision‑making.
FAQs
1. What does “Master in Observability Engineering” mean in practice?
It means you can take responsibility for observability strategy: what to measure, how to instrument, what pipelines to build, and how to support multiple teams with shared platforms. It is less about a job title and more about the depth of capability you bring.
2. Is MOE mostly theory or mostly hands‑on?
The program mixes conceptual explanation with labs and scenario‑based exercises. You learn frameworks and then immediately apply them to sample or simulated production environments.
3. Can MOE help me move from testing or support to SRE/DevOps?
Yes, especially if you already deal with incidents or bugs. MOE gives you a structured way to collect and use data, which is highly valued in SRE and DevOps roles.
4. Does MOE include incident simulations?
Public descriptions mention real‑time scenarios, incident diagnosis, and case‑study style learning, though exact exercises can differ by batch. Expect to practice troubleshooting using observability tools, not just reading about them.
5. How does MOE support long‑term learning after the course?
The curriculum is designed as a starting point; you can keep applying the same patterns as your systems and tools evolve. Combining MOE with paths like MDE gives you a multi‑year roadmap rather than a one‑time class.
6. Is MOE suitable for people managing large teams?
Yes, engineering managers responsible for uptime, performance, and cost gain a language to discuss observability with their teams and leadership. It also helps them make better decisions about tooling investments and SLO policies.
7. How does MOE complement Master in DevOps Engineering?
MDE gives you wide coverage across DevOps, DevSecOps, and SRE, while MOE gives deep coverage in observability. Together, they cover the full journey from code to deployment to reliability and insight.
8. Why is now a good time to pursue MOE?
Because observability has shifted from “nice to have” to “business‑critical” in many organizations, and there is still a shortage of people with real depth in this area. Getting ahead now puts you in a strong position as more companies formalize Observability and SRE practices.
Conclusion
Observability is quickly becoming one of the most important capabilities in modern software and infrastructure teams. The Master in Observability Engineering certification from DevOpsSchool gives you a structured, practice‑oriented path to move from basic monitoring to true observability mastery.For DevOps Engineers, SREs, Platform and Cloud Engineers, Security and Data professionals, FinOps practitioners, and Engineering Managers, MOE connects directly to daily work and long‑term career growth. Combined with adjacent master‑level programs like Master in DevOps Engineering, it helps you build a complete, future‑ready profile in modern engineering, operations, and reliability.